前々から理想としては歌うとVOCALOIDちっくにそれをリアルタイムに他の人が歌うようになる、というものを作ってみたかったのですが、日本語音声解析部分で断念してました。
日本語音声解析はある程度の単語を解析したうえで文字列を返す、というものなのでリアルタイムに1音1音返すものではないのでマッチせず(そういうの開発すればできるんだろうけど、、)というのと、そもそも日本語音声解析なのでもちろん日本にしか情報はなく、、、
ということでとりあえず、日本語音声解析部分は置いといて音程と音量によって同じように別の音声ファイルを再生する、というのを試してみました。
実際のパッチはこんな感じ
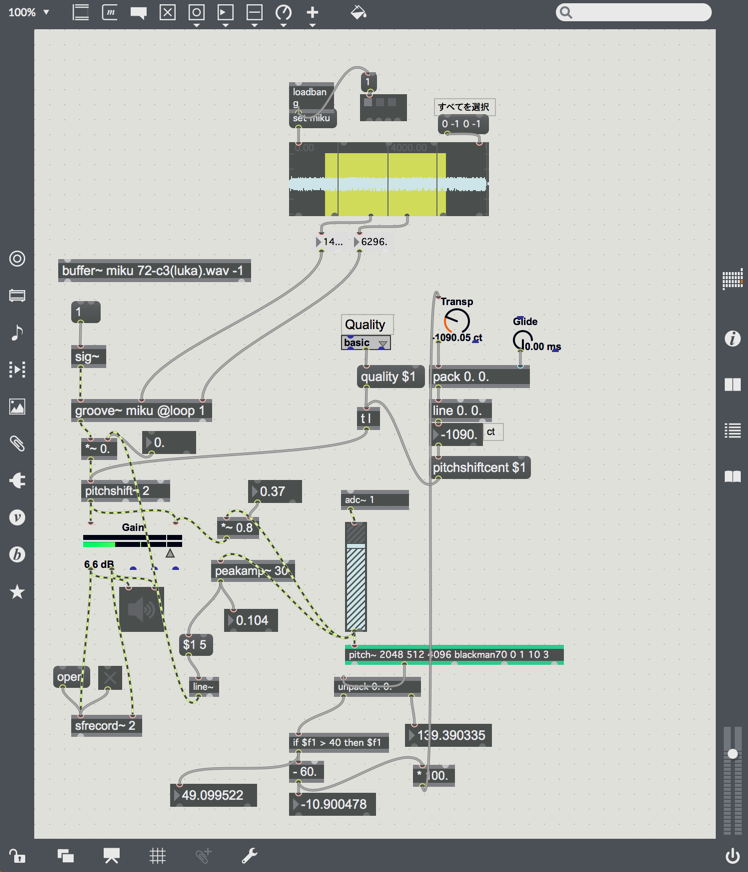
パッチの内容は以下
- C3を基準にした音声ファイルを一つ用意し、groove~でループ
- fiddle~の後継のpitch~を使ってピッチを検出。既にMIDI化したものと周波数の2つがでるがMIDIの方を利用
- ノートナンバー40以下は無視する
- pitchshift~という標準のオブジェクトを使って(昔はこれに変わるの自分で組んだ記憶)grooveの音声のピッチを調整
- 入力された音の音量にあわせてサンプル再生の音量も変わる
単純にはまったところとしては、externalオブジェクトが64bitに対応してないのが多いので32bitモードで起動する、というところでした。
実際に利用した音声ですが、まずは元のファイルのmikuのC3のサンプルファイル。
次に娘版。わかりやすいように元の音は右チャンネルに、音声サンプルの最終的な出音は左右のチャンネルに流したものを録音しています。
続いて私がテストした版
といったように、結構元の音程といい感じに合うようにできてるかなと思います。
今回は元ファイルが初音ミクですが、実際の人の声を用意すればその人の声で擬似的に歌える(歌詞はムリ)のかなぁと思いつつ、日本語リアルタイム解析はディレイも考えるとむずかしいよなぁ。。と思う今日このごろでした(^_^;)


